


Scraping student data from a library database using worker pools in go.
So, I was playing around with a college's library site when I noticed they were using the default creds for their library management software. This leaves the data of mode than 8000 students vulnerable to scraping using their default creds or by using sql injection on the librarian console (yes, people still don't use prepared statement in commercial software).
So I decided to to just that. Scraping data of current (and past) students studying in the college. All in good faith (obviously).
Here was the plan ->

generating enums :
I don't know what the complete roll numbers of all the students are. But I do know what first 4 digits represent.
If I could brute-force the rest of the 5 digits without breaking or alerting the library servers I could hypothetically scan for the successful hits and scrape the data.
So I wrote this program that takes the year of students as input and generates all the permutations of the roll numbers. Then stores it in a Postgres table with the following fields.

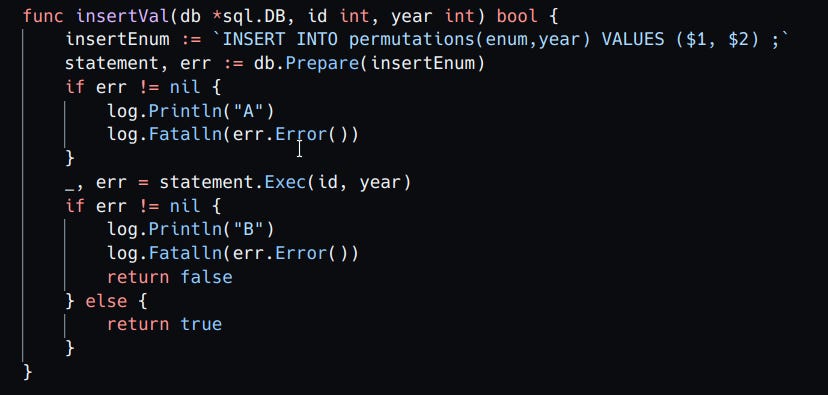

We'll use this table as a reference of the successful hits and the the enums not yet touched.
reverse engineering the login flow :
Next logical step is figuring out the api endpoints and see how server authenticates the requests one logged in.
In this case one you submit the used id and password, it called a perl script which sends back session token as cookie header if you were authenticated successfully.
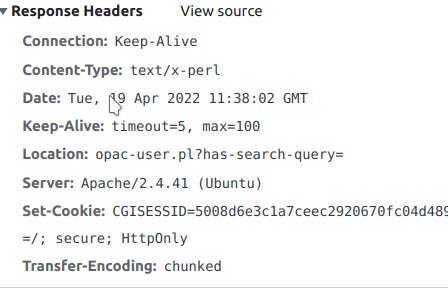
The gotcha in this login flow is that the server still sends a 200-Ok request with with a session cookie even if you weren't logged successfully.
So to figure out if the uid-password combo was correct, I had to see what was inside the request, parse it and see if I was logged in successfully.
This snippet of code does just that. It scans the 45 character of the response data and checks of it a particular character. If yes, then classifies this as a successful hit and stores the session token.

sending 500k request's to the server concurrently without raising any red flags :
the problem with using brute-force to find out successful enum hits is that every request take at least 1.4 seconds to complete (even on local network) and 2+ seconds if it is a successful hit. This is server side latency and there;s nothing I can do about it.
I however can uses go's robust inbuilt concurrency model to send a lot of requests concurrently . This presents the risk of dosing the library's server and getting my IP blocked.
The solution of all of this is using a concurrency pattern called worker pools. Worker pools uses go's inbuild channels to build a jobs queue from which my (limited) pool of goroutines can concurrently fetch jobs to do.
This video explains all of this and more pretty lucidly.
This snippet of code makes two separate channels, creates n number of go routines and then fills the jobs channels with data it fetched from the permutation's db. At last it waits for the workers to finish their jobs by listening to the results channels.
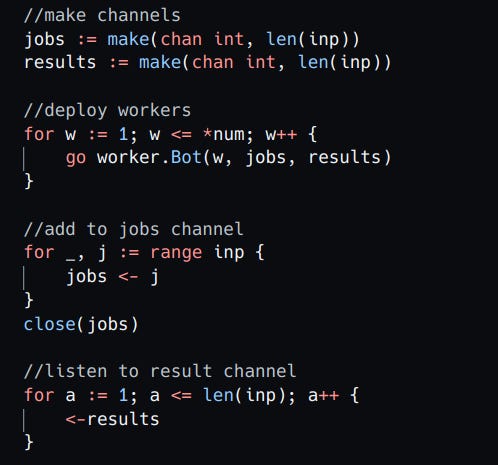
parsing all the data from the profiles page :
each student has a my profile page in which they can change their personal details all of this comes pre-hydrated as an HTML page and NOT as a json response which means I had to write my own parser.
Go's inbuilt html parsing engine is way too complicated for my wrap my head around in the time-frame of this project. So I went with an awesome library called goquery which implements jquery in native go and is used by other major scraping libs like colly.
The parser I wrote is way too ugly and and duck-taped together to be discussed in this post but ye can have a look at it here.
handling images :
to scrape images I wrote a separate module which requested the png (<60kb) form the server, converted it into base64 url string compatible with chrome and chucked it into my database.

Other notes :
for my database I went with postgres as its awesome and I had a some experience writing highly concurrent go apps with it. It does not disappoint or fuck-up ever unlike its nosql counterparts.
I was able to run ~50 gophers concurrently without experiencing some sort of throttling.
Modularising the apps smary can save you and others tonns of headches and makes the overall experice of working on an project more fun.
I still don't how how to write good tests form my code.
final result :
this was the final size of the db after hitting the library server 500k times scraping data of more than than 8000 students.


")