
Making a better twitter recommendation engine. Part(1) Scraping Following's Followings.
I have a simple need. Show me tweets of people who are followed by the accounts I follow (but I don't). I believe this would create a much better "For You" page than whatever shit elon's been cooking in there (seriously.... the for you page is so bad its honestly appalling). I'll add momentum based recommendation (trending) later once I have a system to reliably get the tweets of the people who I follow, follow (if you get what I mean 😅)
So as for part 1 lets make a twitter scrape that scrapes all the handles of accounts a person follows. To help me make sense of this clusterfuck of an API I'm gonna use the divine powers of GPT4 .
Its honestly pretty surprising how good is gpt, at understanding the graph api twitter uses. It reduced the time to build this thing from like a weekend to like a couple of hours.Freakin magical.
This is the request twitter makes to make the initial fetch of the follower list :
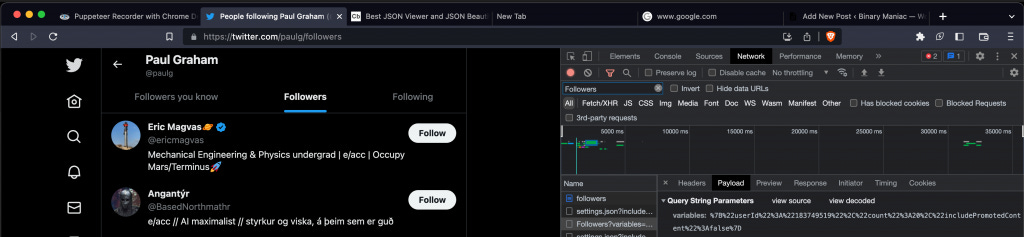
Looking closely these are the variables encoded in the URL of the request :
{"userId":"183749519","count":20,"includePromotedContent":false}
{"blue_business_profile_image_shape_enabled":true,"responsive_web_graphql_exclude_directive_enabled":true,"verified_phone_label_enabled":true,"responsive_web_graphql_timeline_navigation_enabled":true,"responsive_web_graphql_skip_user_profile_image_extensions_enabled":false,"tweetypie_unmention_optimization_enabled":true,"vibe_api_enabled":true,"responsive_web_edit_tweet_api_enabled":true,"graphql_is_translatable_rweb_tweet_is_translatable_enabled":true,"view_counts_everywhere_api_enabled":true,"longform_notetweets_consumption_enabled":true,"tweet_awards_web_tipping_enabled":false,"freedom_of_speech_not_reach_fetch_enabled":false,"standardized_nudges_misinfo":true,"tweet_with_visibility_results_prefer_gql_limited_actions_policy_enabled":false,"interactive_text_enabled":true,"responsive_web_text_conversations_enabled":false,"longform_notetweets_rich_text_read_enabled":true,"responsive_web_enhance_cards_enabled":false}In the second scroll of the list a variable called cursor gets added to the request which specified the sub-list of followers to fetch. This cursor is returned from the previous request as the timeline cursor.

{"userId":"183749519","count":20,"cursor":"1763689340909851626|1649001226504765398","includePromotedContent":false}
So to fetch all the list of followers of an account I just need to loop this request with different cursor till the beginning of cursor reaches 0. ie the request returns 0|xyz as the cursor value.
Now to build the parser I could study the whole response orrrrr I can just pass the resonse to GPT4 and ask it to build a parser for me 🤯.


The pagination code was Incorrect as i wasn't specific enough to what exact attribute to extract so I ask it to modify the code.


All of this worked the first try OFC. Now the only thing left was to loop this shit till the end of cursor. For this I gave it all the code it had previously written to modify and make the final script.

aaaand It worked. On the first attempt nonetheless lmao.

It was truly wild seeing it understand the api response so well.
I am planning to create an llm agent that automates all of this by just giving it a url of a webpage and a prompt about what things to scrape... but first lemme fix my twitter recommendations real quick.